Chapter 1 Pre Submission Correctness Test
Chapter description
Before we can begin writing a submission correctness test, we first need to create and develop the other elements of a DataCamp light exercise. This chapter serves as a very brief introduction to the other elements of a DataCamp light exercise, as well as the standard notation utilized in the regression book {link here?}.
1.1 Pre-Exercise Code
In this section, you will learn:
-The code indicating we are writing the pre-exercise code
-The importance and usefulness of the pre-exercise code
The pre-exercise code is a set of code that gives you the ability to run code “behind the scenes”. Typically, these are used to create/assign data to variable names used by the learner. This could be as simple as assigning x to be 23, or as complex as loading in a dataframe, removing/adding columns, renaming columns, and then renaming the whole dataframe.
To add pre-exercise code to your exercise, you will first have to create a new section code in an R markdown document, which will create something that looks like the following:
Now, we need to modify a few arguments inside “{r}”. Specifically we need to modify the following: “ex”, “type”, and “tut”. This will look something like the following:

For a given set of pre-exercise code, hint, soluton, sct, and sample code, all of the “ex” should be the same. This way DataCamp Light knows to combine them into a single exercise, as opposed to making each one belong to its own exercise.
1.2 Solution
In this section, you will learn:
-The code indicating we are writing the solution code
-The importance and usefulness of the solution code
The soltuion code quite simply the “perfect” solution to the problem asked. Ideally, this is done in as few lines as possible, but as many lines as needed. Basially you want it to be a concise answer, but not too concise where it becomes hard to understand or write an SCT for.
This gets written like normal R code you would write to solve the problem.
Once again, this will require making a new r chunk in markdown, and modifying the “ex”, “type”, and “tut” arguments. This will looking something like the following for the solution code:

1.3 Sample Code
In this section, you will learn:
-The code indicating we are writing the sample code
-The importance and usefulness of the sample code
The sample code acts as a framework for the code the learner should use to solve the code. It can be as simple as having multiple comments telling the learner what to do. This could be something like:
#Find the mean of `miles per gallon` using the dataframe `mtcars`, and assign the value to `mean.mpg`On the other hand, you could also put your solution code as your sample code, and then remove a few arguments to allow a learner to understand better how certain functions work, and what arguments they need to plug in. For example, if the question asked a learner to generate 4 random numbers from the exponential distribution with mean 20, you could give them the following code:
random.numbers=rexp(n=___,rate=____)Then, all the learner has to do is plug in n=4 and rate=1/20 in order to get the correct answer.
Once again, this will require making a new r chunk in markdown, and modifying the “ex”, “type”, and “tut” arguments. This will looking something like the following for the sample code:

1.4 Hint
In this section, you will learn:
-The code indicating we are writing the hint
-The importance and usefulness of using hint
The hint, very simply, creates a button that the learner can press to recieve a pre-written hint about how to go about solving the problem. For example, if the question called for the learner to round a value x to 3 digits, the hint could say something like:
"to round a number, you can use `round(x,digits), where x is the number you want to round, and digits is how many digits you would like."Once again, this will require making a new r chunk in markdown, and modifying the “ex”, “type”, and “tut” arguments. This will looking something like the following for the solution code:

1.5 Example
Below is the code used in the first exercise for the linear regression book. First you will see a picture of the code, and then you will see what the code actually looks like. The only other thing that was added was the assignment text and instructions which are both just standard text typed before the hint chunk.
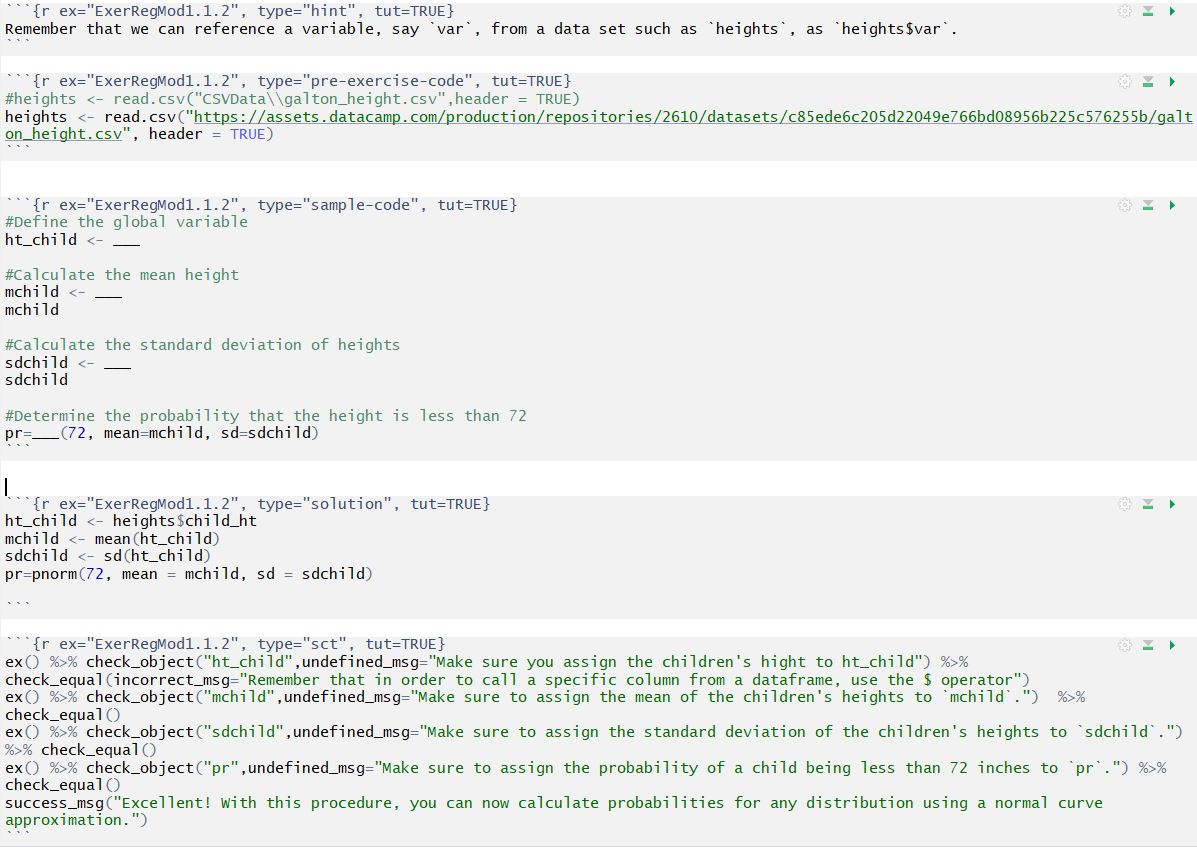
1.5.1 Exercise. Fitting Galton’s height data
Assignment Text
The Galton data has already been read into a dataframe called heights. These data include the heights of 928 adult children child_ht, together with an index of their parents’ height parent_ht. The video explored the distribution of the parents’ height; in this assignment, we investigate the distribution of the heights of the adult children.
Instructions
- Define the height of an adult child as a global variable
- Use the function mean() to calculate the mean and the function sd() to calculate the standard deviation
- Use the normal approximation and the function pnorm() determine the probability that an adult child’s height is less than 72 inches
1.6 More Resources
If you are looking for more information, try looking at the folliwng webpages: [https://datacamp.github.io/tutorial/][https://instructor-support.datacamp.com/]
As a note, writing exercises in Datacamp works exactly the same as DataCamp Light, so anything you find in regards to DataCamp can more than likely be applied to DataCamp Lite