Chapter 2 Basic Linear Regression
Chapter description
This chapter considers regression in the case of only one explanatory variable. Despite this seeming simplicity, many deep ideas of regression can be developed in this framework. By limiting ourselves to the one variable case, we can illustrate the relationships between two variables graphically. Graphical tools prove to be important for developing a link between the data and a predictive model.
2.1 Correlation
In this section, you learn how to:
- Calculate and interpret a correlation coefficient
- Interpret correlation coefficients by visualizing scatter plots
2.1.1 Video
Video Overhead Details
A Details. Wisconsin lottery data description
Lot <- read.csv("CSVData\\Wisc_lottery.csv")
#Lot <- read.csv("https://assets.datacamp.com/production/repositories/2610/datasets/a792b30fb32b0896dd6894501cbab32b5d48df51/Wisc_lottery.csv", header = TRUE)
str(Lot)'data.frame': 50 obs. of 3 variables:
$ pop : int 435 4823 2469 2051 13337 17004 38283 9859 4464 20958 ...
$ sales : num 1285 3571 2407 1224 15046 ...
$ medhome: num 71.3 98 58.7 65.7 96.7 66.4 91 61 91.5 68.8 ...B Details. Summary statistics
#options(scipen = 100, digits = 4)
#numSummary(Lot[,c("pop", "sales")], statistics = c("mean", "sd", "quantiles"), quantiles = c(0,.5,1))
(as.data.frame(psych::describe(Lot)))[,c(2,3,4,5,8,9)]
#Rcmdr::numSummary(Lot[,c("pop", "sales")], statistics = c("mean", "sd", "quantiles"), quantiles = c(0,.5,1)) n mean sd median min max
pop 50 9311.040 11098.15695 4405.500 280.0 39098.0
sales 50 6494.829 8103.01250 2426.406 189.0 33181.4
medhome 50 57.092 18.37312 53.900 34.5 120.0C Details. Visualizing skewed distributions
par(mfrow = c(1, 2))
hist(Lot$pop, main = "", xlab = "population")
hist(Lot$sales, main = "", xlab = "sales")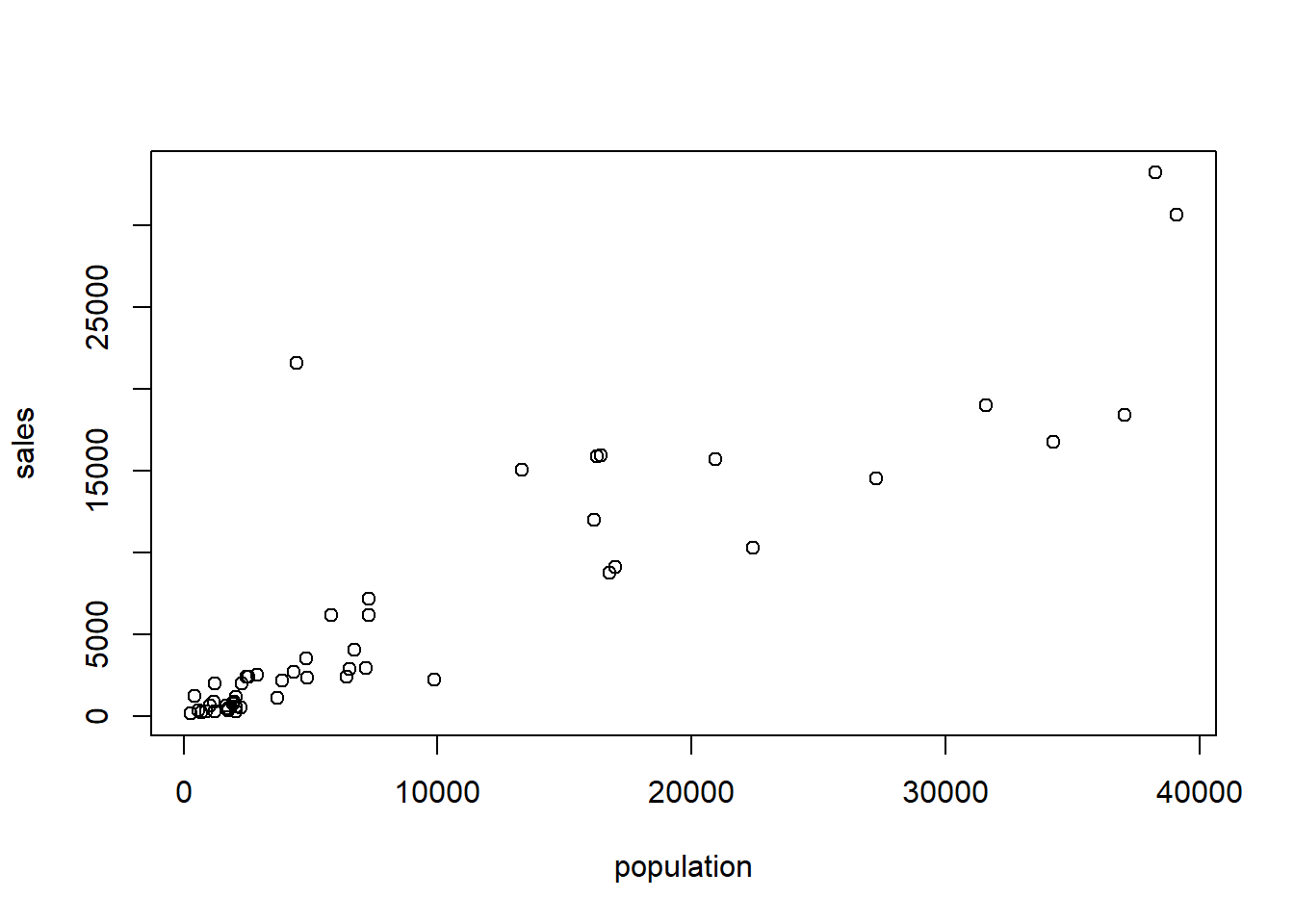
D Details. Visualizing relationships with a scatter plot
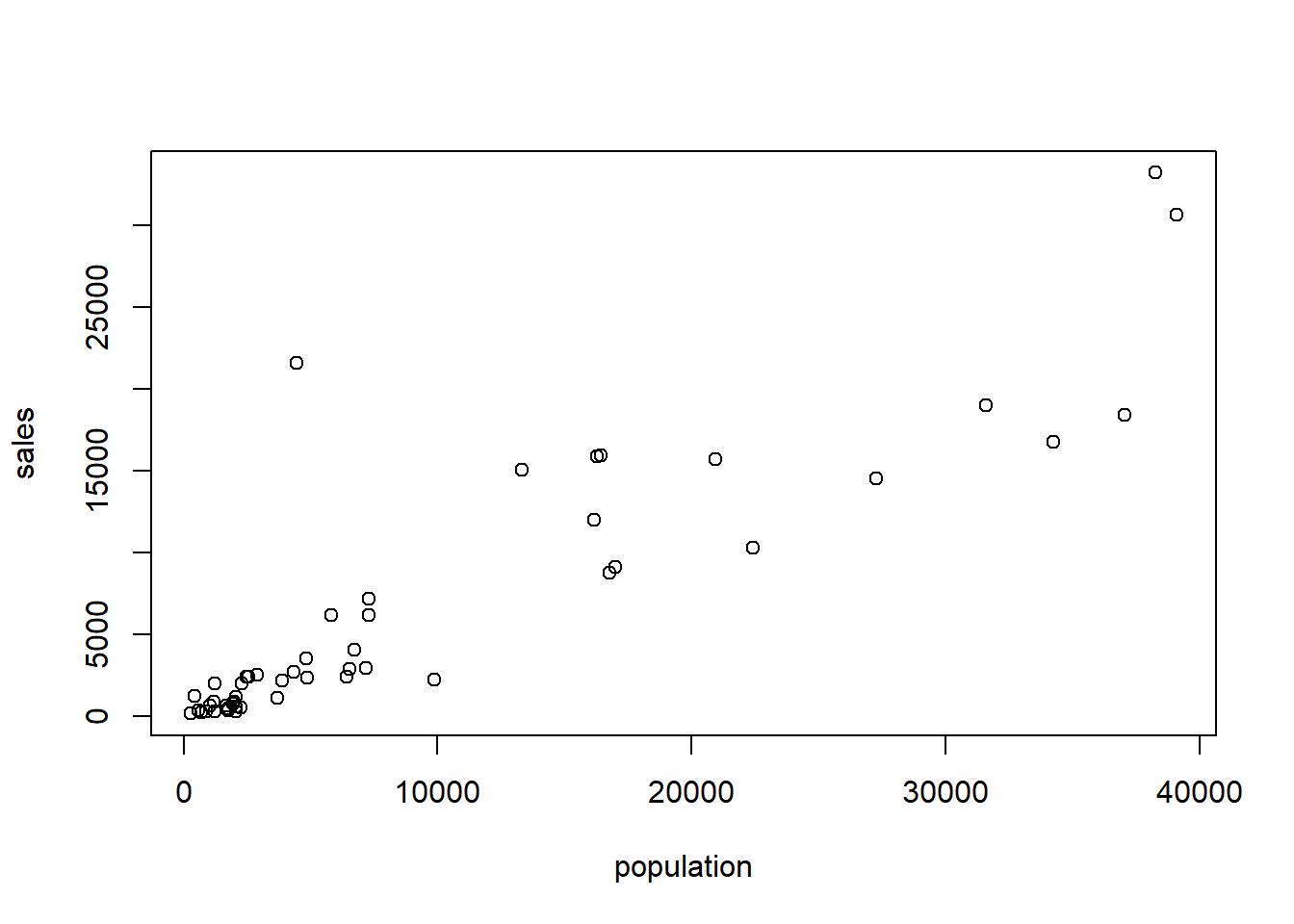
2.1.2 Exercise. Correlations and the Wisconsin lottery
Assignment Text
The Wisconsin lottery dataset, Wisc_lottery,has already been read into a dataframe Lot.
Like insurance, lotteries are uncertain events and so the skills to work with and interpret lottery data are readily applicable to insurance. It is common to report sales and population in thousands of units, so this exercise gives you practice in rescaling data via linear transformations.
Instructions
- From the available population and sales variables, create new variables in the dataframe
Lot,pop_1000andsales_1000that are in thousands (of people and of dollars, respectively). - Create summary statistics for the dataframe that includes these new variables.
- Plot
pop_1000versussales_1000. - Calculate the correlation between
pop_1000versussales_1000using the function cor(). How does this differ between the correlation between population and sales in the original units?
2.2 Method of least squares
In this section, you learn how to:
- Fit a line to data using the method of least squares
- Predict an observation using a least squares fitted line
2.2.1 Video
2.2.1.1 Video Overheads
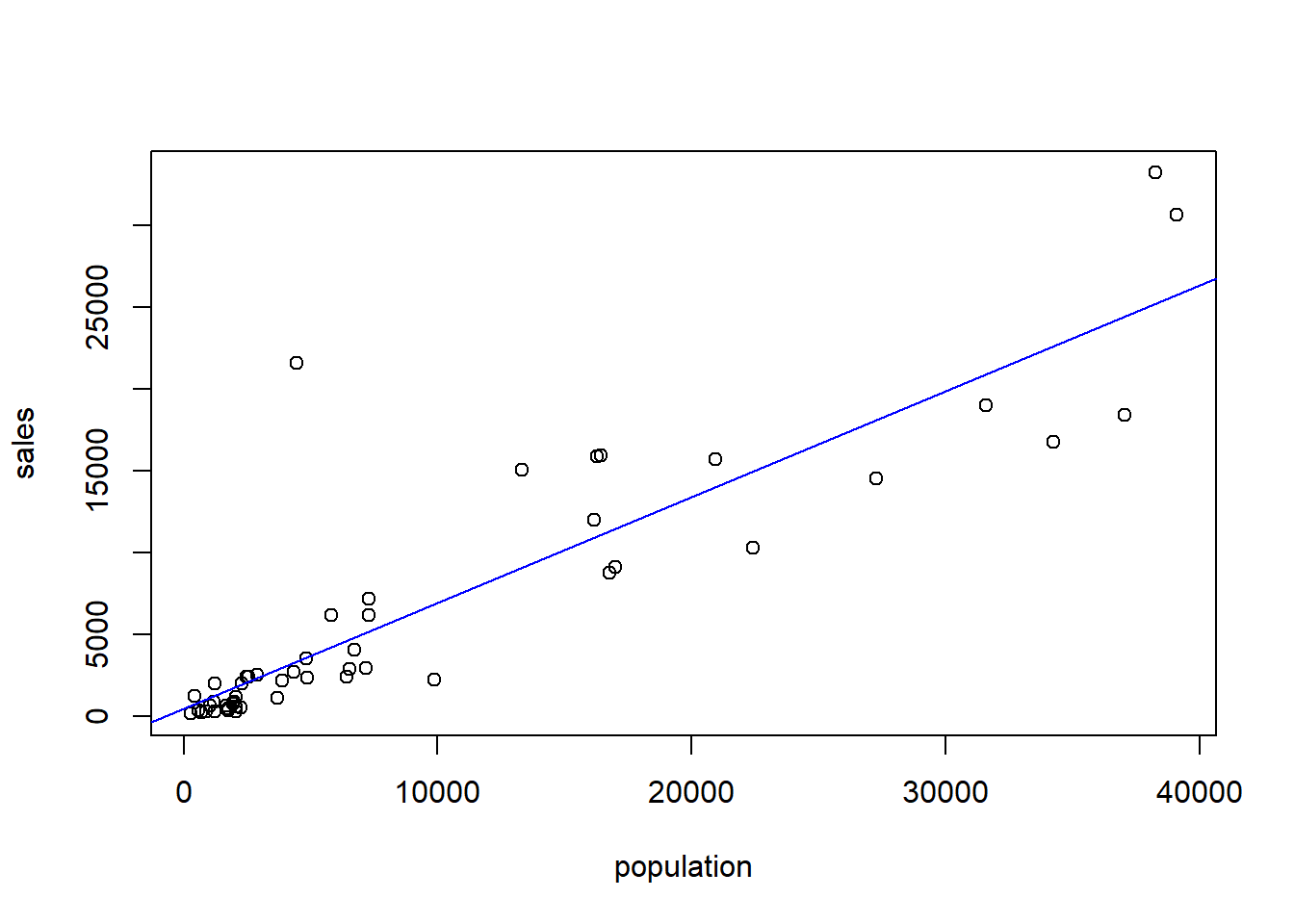
A Details. Where to fit the line?
model_blr <- lm(sales ~ pop, data = Lot)
plot(Lot$pop, Lot$sales,xlab = "population", ylab = "sales")
abline(model_blr, col="blue")
abline(0,1, col="red")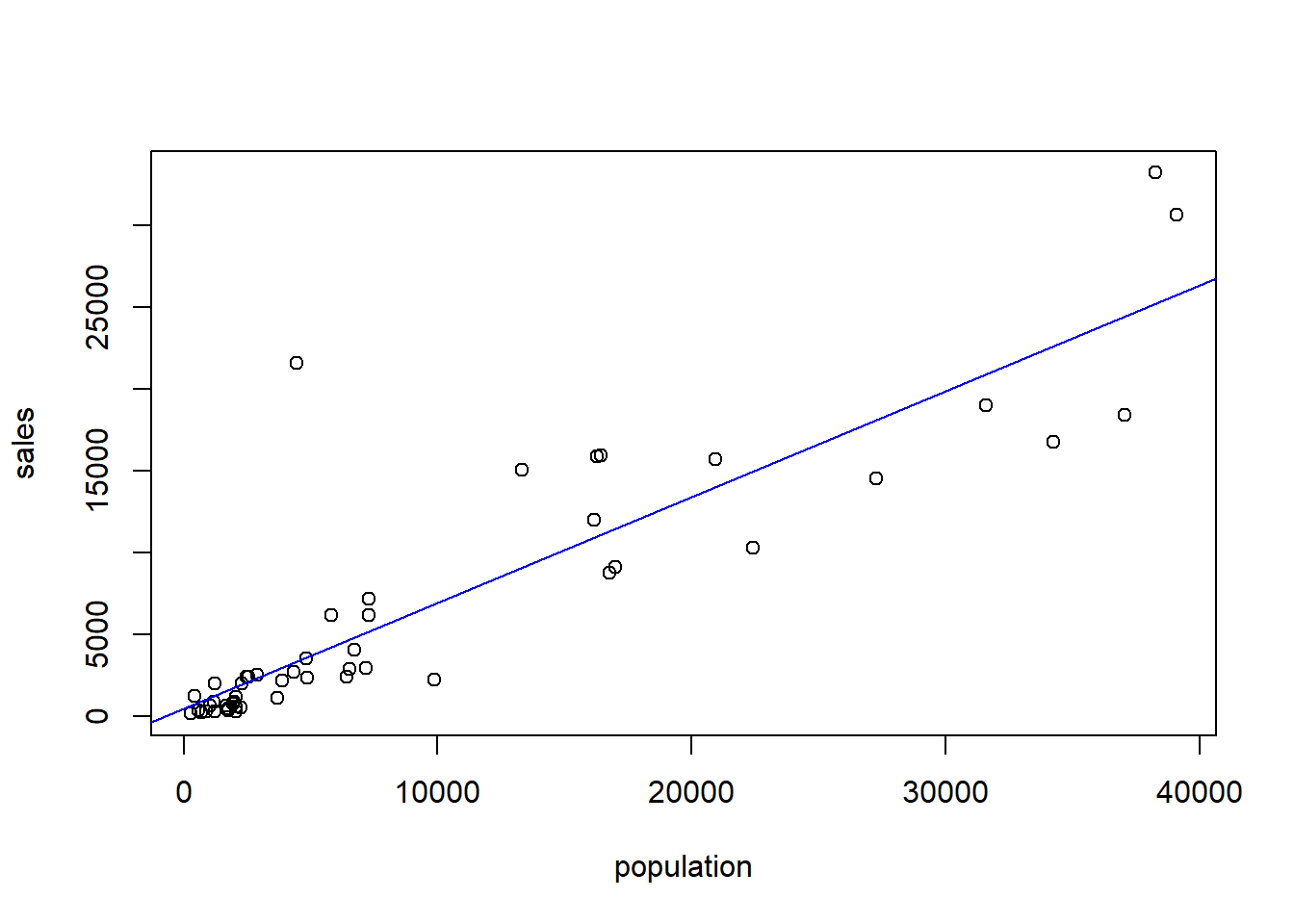
B Details. Method of least squares
- For observation \(\{(y, x)\}\), the height of the regression line is \[b_0 + b_1 x.\]
- Thus, \(y - (b_0 + b_1 x)\) represents the deviation.
- The sum of squared deviations is \[SS(b_0, b_1) = \sum (y - (b_0 + b_1 x))^2 .\]
- The method of least squares – determine values of \(b_0, b_1\) that minimize \(SS\).
2.2.2 Exercise. Least squares fit using housing prices
Assignment Text
The prior video analyzed the effect that a zip code’s population has on lottery sales. Instead of population, suppose that you wish to understand the effect that housing prices have on the sale of lottery tickets. The dataframe Lot, read in from the Wisconsin lottery dataset Wisc_lottery, contains the variable medhome which is the median house price for each zip code, in thousands of dollars. In this exercise, you will get a feel for the distribution of this variable by examining summary statistics, examine its relationship with sales graphically and via correlations, fit a basic linear regression model and use this model to predict sales.
Instructions
- Summarize the dataframe
Lotthat containsmedhomeandsales. - Plot
medhomeversussales. Summarize this relationship by calculating the corresponding correlation coefficient using the function cor(). - Using the function lm(), regress
medhome, the explanatory variable, onsales, the outcome variable. Display the regression coefficients to four significant digits. - Use the function predict() and the fitted regression model to predict sales assuming that the median house price for a zip code is 50 (in thousands of dollars).
2.3 Understanding variability
In this section, you learn how to:
- Visualize the ANOVA decomposition of variability
- Calculate and interpret \(R^2\), the coefficient of determination
- Calculate and interpret \(s^2\) the mean square error
- Explain the components of the ANOVA table
2.3.1 Video
Video Overhead Details
A and B Details. Visualizing the uncertainty about a line
par(mar=c(2.2,2.1,.2,.2),cex=1.2)
x <- seq(-4, 4, len=101)
y <- x
plot(x, y, type = "l", xlim=c(-3, 4), xaxt="n", yaxt="n", xlab="", ylab="")
axis(1, at = c(-1, 1),lab = expression(bar(x), x))
axis(2, at = c(-1, 1, 3),lab = expression(bar(y), hat(y), y), las=1)
abline(-1, 0, lty = 2)
segments(-4, 1, 1, 1, lty=2)
segments(-4, 3, 1, 3, lty = 2)
segments(1, -4, 1, 3, lty = 2)
segments(-1, -4, -1, -1, lty = 2)
points(1, 3, cex=1.5, pch=19)
arrows(1.0, 1, 1.0, 3, code = 3, lty = 1, angle=15, length=0.12, lwd=2)
text(1.3, 2.2, expression( y-hat(y)),cex=0.8)
text(-.3,2.2,"'unexplained' deviation", cex=.8)
arrows(1.0, -1, 1.0, 1, code = 3, lty = 1, angle=15, length=0.12, lwd=2)
text(1.85, 0, expression(hat(y)-bar(y) == b[1](x-bar(x)) ), cex=0.8 )
text(2.1, -0.5, " 'explained' deviation", cex=0.8)
arrows(-1, -1.0, 1, -1.0, code = 3, lty = 1, angle=15, length=0.12, lwd = 2)
text(0, -1.3, expression( x-bar(x)), cex=0.8 )
text(3.5, 2.7, expression( hat(y)== b[0]+ b[1]*x), cex=0.8 )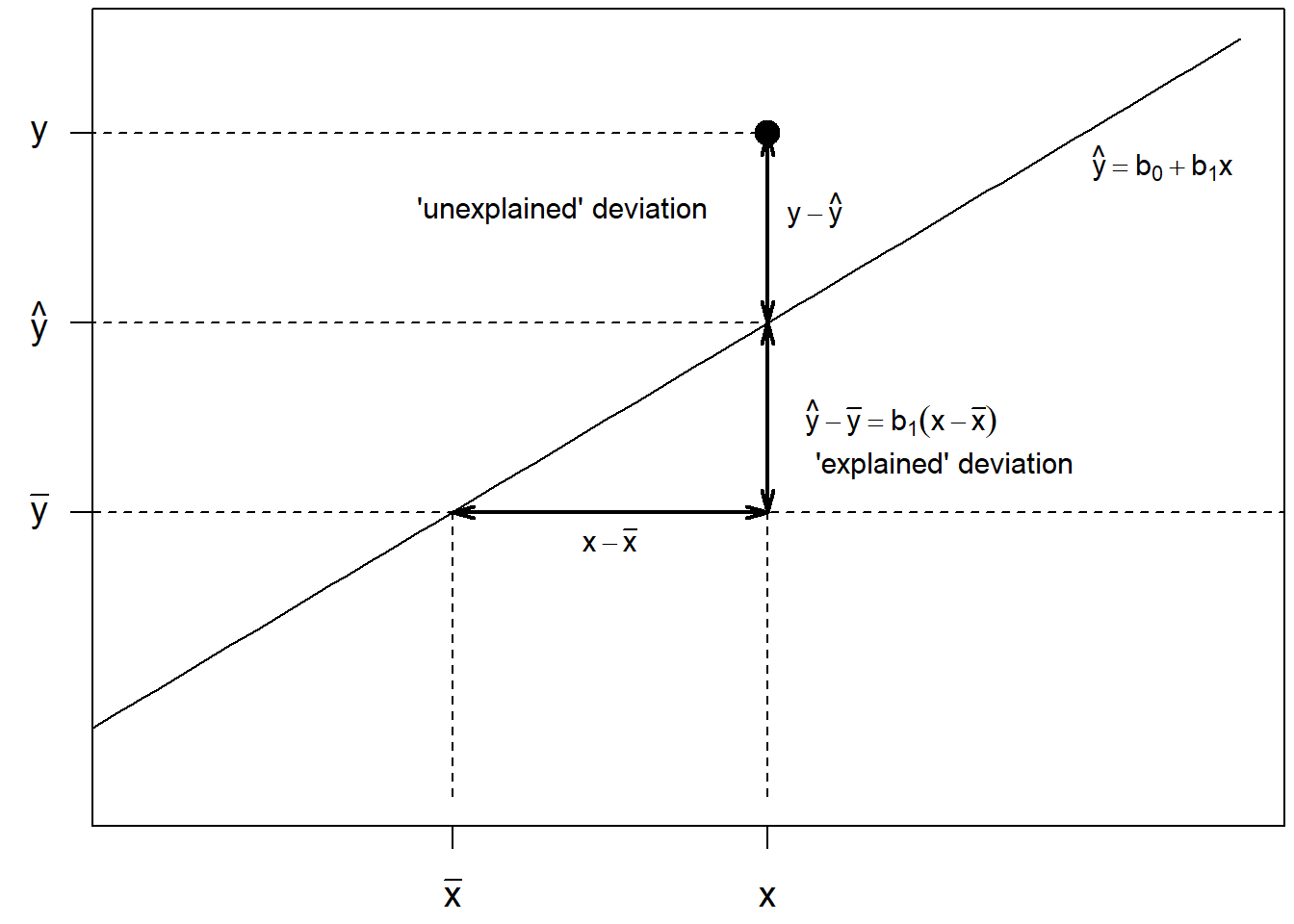
C, D and E Details. ANOVA Table
model_blr <- lm(sales ~ pop, data = Lot)
anova(model_blr)
sqrt(anova(model_blr)$Mean[2])
summary(model_blr)$r.squaredAnalysis of Variance Table
Response: sales
Df Sum Sq Mean Sq F value Pr(>F)
pop 1 2527165015 2527165015 175.77 < 2.2e-16 ***
Residuals 48 690116755 14377432
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
[1] 3791.758
[1] 0.78549692.3.2 Exercise. Summarizing measures of uncertainty
Assignment Text
In a previous exercise, you developed a regression line to fit the variable medhome, the median house price for each zip code, as a predictor of lottery sales. The regression of medhome on sales has been summarized in the R object model_blr.
How reliable is the regression line? In this excercise, you will compute some of the standard measures that are used to summarize the goodness of this fit.
Instructions
- Summarize the fitted regression model in an ANOVA table.
- Determine the size of the typical residual, \(s\).
- Determine the coefficient of determination, \(R^2\).
2.3.3 Exercise. Effects of linear transforms on measures of uncertainty
Assignment Text
Let us see how rescaling, a linear transformation, affects our measures of uncertainty. As before, the Wisconsin lottery dataset Wisc_lottery has been read into a dataframe Lot that also contains sales_1000, sales in thousands of dollars, and pop_1000, zip code population in thousands. How do measures of uncertainty change when going from the original units to thousands of those units?
Instructions
- Run a regression of
poponsales_1000and summarize this in an ANOVA table. - For this regression, determine the \(s\) and the coefficient of determination, \(R^2\).
- Run a regression of
pop_1000onsales_1000and summarize this in an ANOVA table. - For this regression, determine the \(s\) and the coefficient of determination, \(R^2\).
Hint. The residual standard error is also available as summary(model_blr1)$sigma. The coefficient of determination is also available as summary(model_blr1)$r.squared.
2.4 Statistical inference
In this section, you learn how to:
- Conduct a hypothesis test for a regression coefficient using either a rejection/acceptance procedure or a p-value
- Calculate and interpret a confidence interval for a regression coefficient
- Calculate and interpret a prediction interval at a specific value of a predictor variable
2.4.1 Video
Video Overhead Details
A Details. Summary of basic linear regression model
Introduce the output in the summary of the basic linear regression model.
Lot <- read.csv("CSVData\\Wisc_lottery.csv", header = TRUE)
#Lot <- read.csv("https://assets.datacamp.com/production/repositories/2610/datasets/a792b30fb32b0896dd6894501cbab32b5d48df51/Wisc_lottery.csv", header = TRUE)
#options(scipen = 8, digits = 4)
model_blr <- lm(sales ~ pop, data = Lot)
summary(model_blr)
Call:
lm(formula = sales ~ pop, data = Lot)
Residuals:
Min 1Q Median 3Q Max
-6046.7 -1460.9 -670.5 485.6 18229.5
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 469.70360 702.90619 0.668 0.507
pop 0.64709 0.04881 13.258 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3792 on 48 degrees of freedom
Multiple R-squared: 0.7855, Adjusted R-squared: 0.781
F-statistic: 175.8 on 1 and 48 DF, p-value: < 2.2e-16B Details. Hypothesis testing
> summary(model_blr)$coefficients
Estimate Std. Error t value Pr(>|t|)
(Intercept) 469.7036 702.90619 0.6682 5.072e-01
pop 0.6471 0.04881 13.2579 1.158e-17C Details. Confidence intervals
5 % 95 %
(Intercept) -709.2276710 1648.6348666
pop 0.5652327 0.7289569
2.5 % 97.5 %
(Intercept) -943.5840183 1882.99121
pop 0.5489596 0.74523D Details. Confidence intervals check
# Just for checking
summary(model_blr)$coefficients[2,1]
summary(model_blr)$coefficients[2,2]
qt(.975, 48)
summary(model_blr)$coefficients[2,1] -
summary(model_blr)$coefficients[2,2]*qt(.975, 48)
confint(model_blr, level = .95)
confint(model_blr, level = .95)[1] 0.6470948
[1] 0.04880808
[1] 2.010635
[1] 0.5489596
2.5 % 97.5 %
(Intercept) -943.5840183 1882.99121
pop 0.5489596 0.74523
2.5 % 97.5 %
(Intercept) -943.5840183 1882.99121
pop 0.5489596 0.745232.4.2 Exercise. Statistical inference and Wisconsin lottery
Assignment Text
In a previous exercise, you developed a regression line with the variable medhome, the median house price for each zip code, as a predictor of lottery sales. The regression of medhome on sales has been summarized in the R object model_blr.
This exercise allows you to practice the standard inferential tasks: hypothesis testing, confidence intervals, and prediction.
Instructions
- Summarize the regression model and identify the t-statistic for testing the importance of the regression coefficient associated with
medhome. - Use the function confint() to provide a 95% confidence interval for the regression coefficient associated with
medhome. - Consider a zip code with a median housing price equal to 50 (in thousands of dollars). Use the function predict() to provide a point prediction and a 95% prediction interval for sales.
2.5 Diagnostics
In this section, you learn how to:
- Describe how diagnostic checking and residual analysis are used in a statistical analysis
- Describe several model misspecifications commonly encountered in a regression analysis
2.5.1 Video
Video Overhead Details
A Details. Unusual observations in regression
- We have defined regression estimates as minimizers of a least squares objective function.
- An appealing intuitive feature of linear regressions is that regression estimates can be expressed as weighted averages of outcomes.
- The weights vary by observation, some observations are more important than others.
- “Unusual” observations are far from the majority of the data set:
- Unusual in the vertical direction is called an outlier.
- Unusual in the horizontal directional is called a high leverage point.
B Details. Example. Outliers and High Leverage Points
outlr <- read.csv("CSVData\\Outlier.csv", header = TRUE)
# FIGURE 2.7
plot(outlr$x, outlr$y, xlim = c(0, 10), ylim = c(2, 9), xlab = "x", ylab = "y")
text(4.5, 8.0, "A")
text(9.8, 8.0, "B")
text(9.8, 2.5, "C")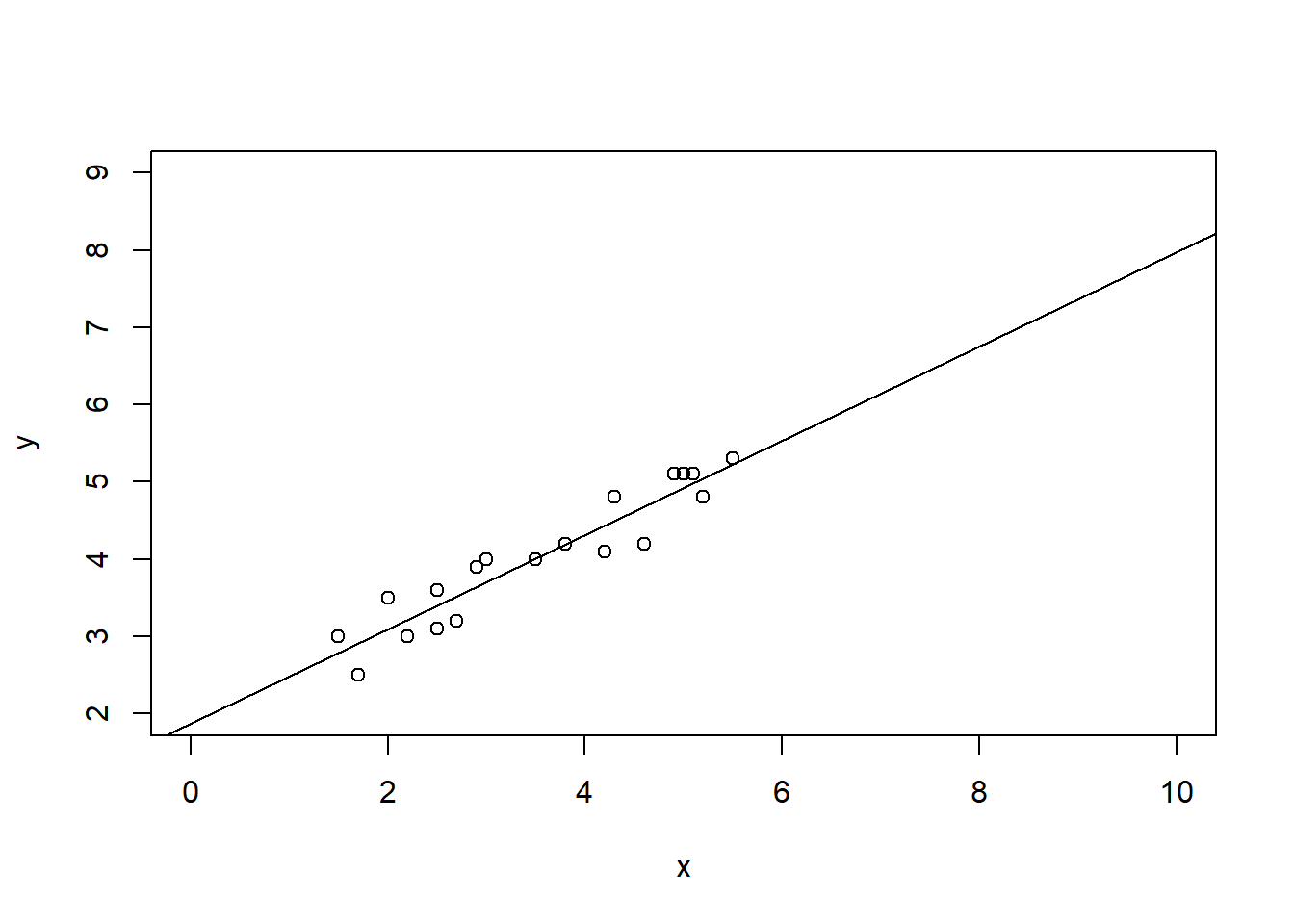
C Details. Regression fit with 19 base observations
model_outlr0 <- lm(y ~ x, data = outlr, subset = -c(20,21,22))
summary(model_outlr0)
plot(outlr$x[1:19], outlr$y[1:19], xlab = "x", ylab = "y", xlim = c(0, 10), ylim = c(2, 9))
abline(model_outlr0)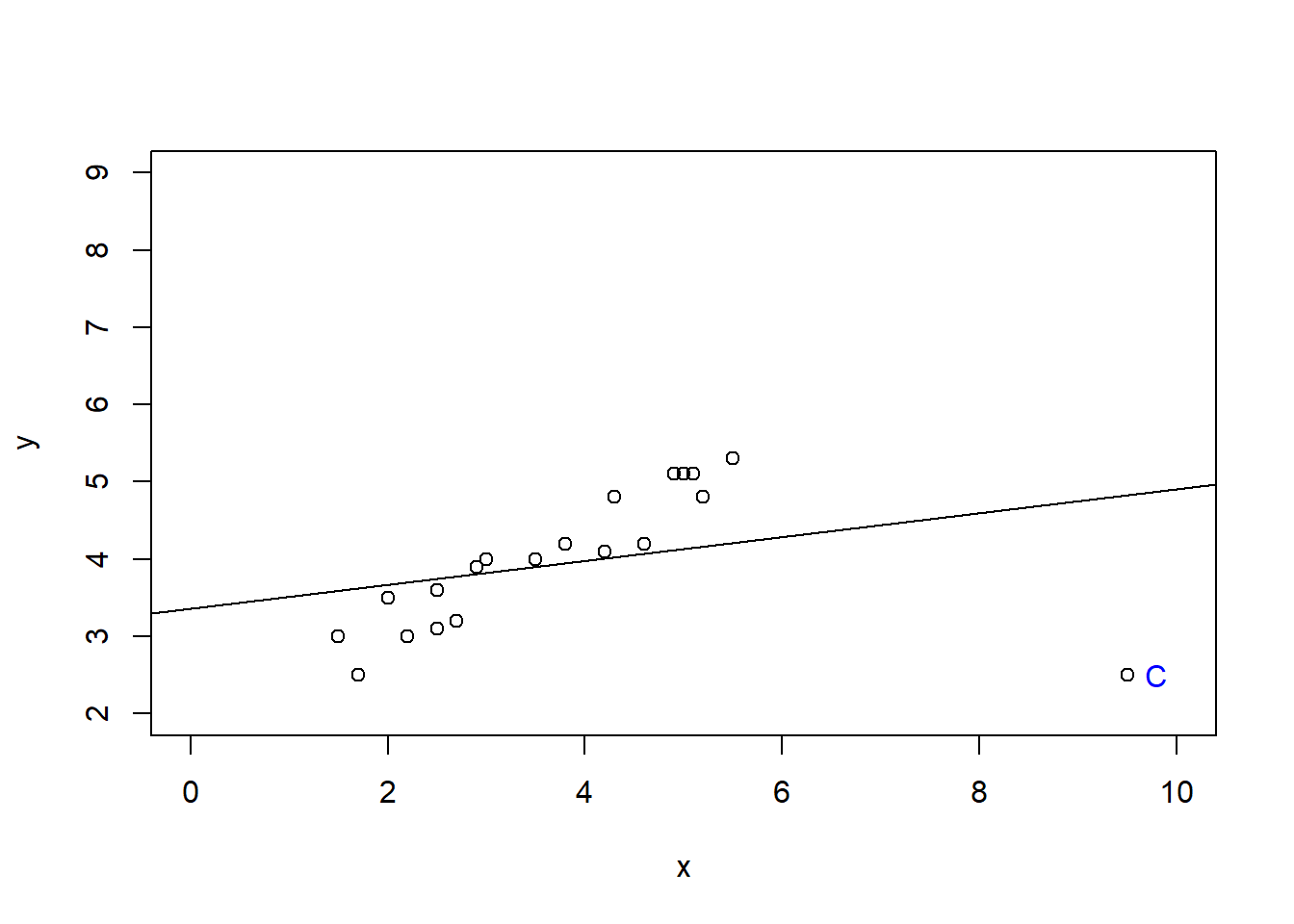
Call:
lm(formula = y ~ x, data = outlr, subset = -c(20, 21, 22))
Residuals:
Min 1Q Median 3Q Max
-0.4790 -0.2708 0.0711 0.2263 0.4094
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.86874 0.19583 9.543 3.06e-08 ***
x 0.61094 0.05219 11.705 1.47e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2883 on 17 degrees of freedom
Multiple R-squared: 0.8896, Adjusted R-squared: 0.8831
F-statistic: 137 on 1 and 17 DF, p-value: 1.471e-09D Details. Regression fit with 19 base observations plus C
model_outlrC <- lm(y ~ x, data = outlr, subset = -c(20,21))
summary(model_outlrC)
plot(outlr$x[c(1:19,22)], outlr$y[c(1:19,22)], xlab = "x", ylab = "y", xlim = c(0, 10), ylim = c(2, 9))
text(9.8, 2.5, "C", col = "blue")
abline(model_outlrC)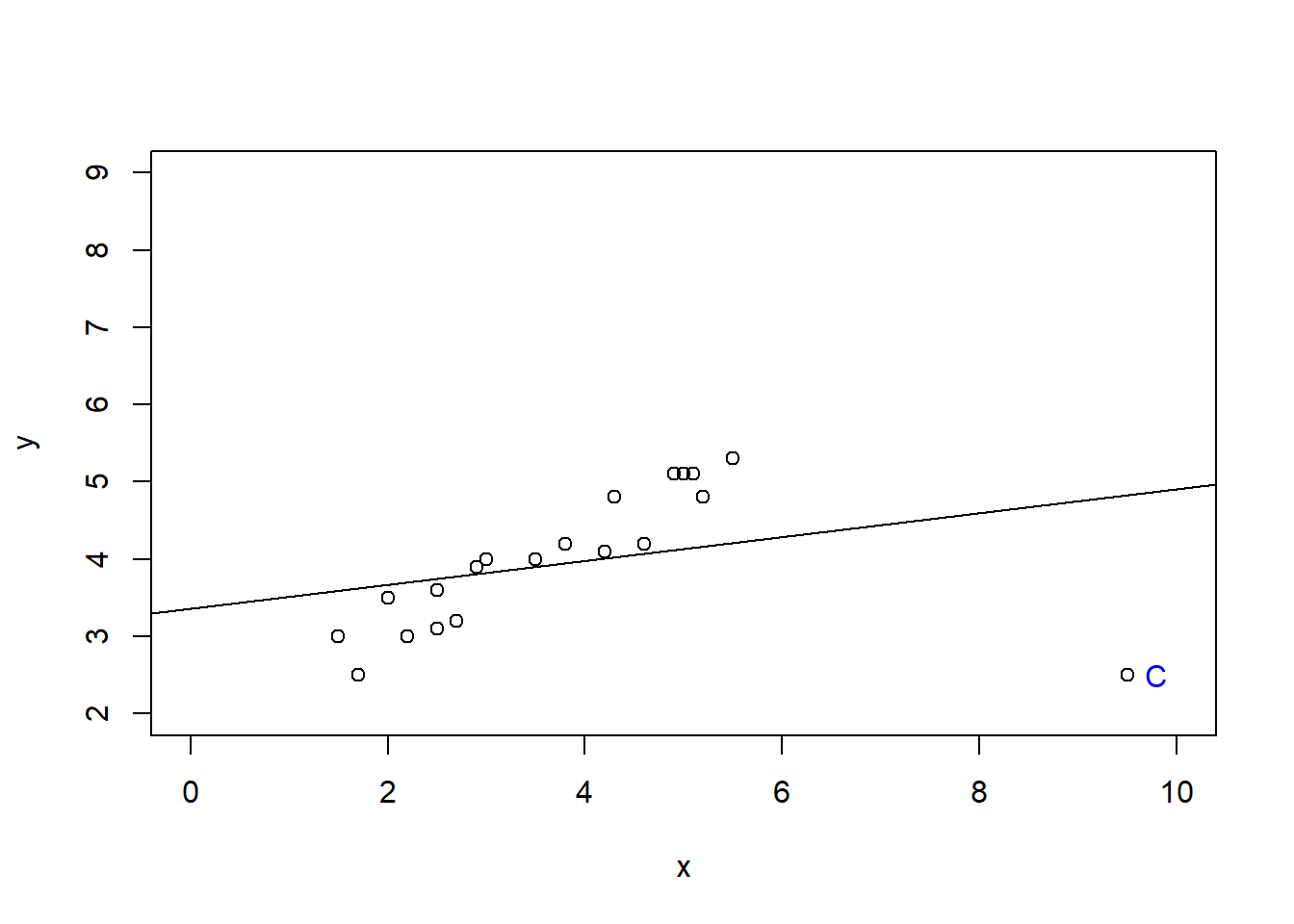
Call:
lm(formula = y ~ x, data = outlr, subset = -c(20, 21))
Residuals:
Min 1Q Median 3Q Max
-2.32947 -0.57819 0.09772 0.67240 1.09097
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.3559 0.4560 7.360 7.87e-07 ***
x 0.1551 0.1078 1.439 0.167
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8648 on 18 degrees of freedom
Multiple R-squared: 0.1031, Adjusted R-squared: 0.0533
F-statistic: 2.07 on 1 and 18 DF, p-value: 0.1674E Details. R code
model_outlr0 <- lm(y ~ x, data = outlr, subset = -c(20,21,22))
summary(model_outlr0)
model_outlrA <- lm(y ~ x, data = outlr, subset = -c(21,22))
summary(model_outlrA)
model_outlrB <- lm(y ~ x, data = outlr, subset = -c(20,22))
summary(model_outlrB)
model_outlrC <- lm(y ~ x, data = outlr, subset = -c(20,21))
summary(model_outlrC)
Call:
lm(formula = y ~ x, data = outlr, subset = -c(20, 21, 22))
Residuals:
Min 1Q Median 3Q Max
-0.4790 -0.2708 0.0711 0.2263 0.4094
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.86874 0.19583 9.543 3.06e-08 ***
x 0.61094 0.05219 11.705 1.47e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2883 on 17 degrees of freedom
Multiple R-squared: 0.8896, Adjusted R-squared: 0.8831
F-statistic: 137 on 1 and 17 DF, p-value: 1.471e-09
Call:
lm(formula = y ~ x, data = outlr, subset = -c(21, 22))
Residuals:
Min 1Q Median 3Q Max
-0.7391 -0.3928 -0.1805 0.1225 3.2689
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.7500 0.5736 3.051 0.006883 **
x 0.6933 0.1517 4.570 0.000237 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8455 on 18 degrees of freedom
Multiple R-squared: 0.5371, Adjusted R-squared: 0.5114
F-statistic: 20.89 on 1 and 18 DF, p-value: 0.0002374
Call:
lm(formula = y ~ x, data = outlr, subset = -c(20, 22))
Residuals:
Min 1Q Median 3Q Max
-0.51763 -0.28094 0.03452 0.23586 0.44581
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.77463 0.15020 11.81 6.48e-10 ***
x 0.63978 0.03551 18.02 5.81e-13 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2849 on 18 degrees of freedom
Multiple R-squared: 0.9474, Adjusted R-squared: 0.9445
F-statistic: 324.5 on 1 and 18 DF, p-value: 5.808e-13
Call:
lm(formula = y ~ x, data = outlr, subset = -c(20, 21))
Residuals:
Min 1Q Median 3Q Max
-2.32947 -0.57819 0.09772 0.67240 1.09097
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.3559 0.4560 7.360 7.87e-07 ***
x 0.1551 0.1078 1.439 0.167
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8648 on 18 degrees of freedom
Multiple R-squared: 0.1031, Adjusted R-squared: 0.0533
F-statistic: 2.07 on 1 and 18 DF, p-value: 0.1674F Details. Visualizing four regression fits
plot(outlr$x, outlr$y, xlim = c(0, 10), ylim = c(2, 9), xlab = "x", ylab = "y")
text(4.5, 8.0, "A", col = "red")
text(9.8, 8.0, "B", col = "green")
text(9.8, 2.5, "C", col = "blue")
abline(model_outlr0)
abline(model_outlrA, col = "red")
abline(model_outlrB, col = "green")
abline(model_outlrC, col = "blue")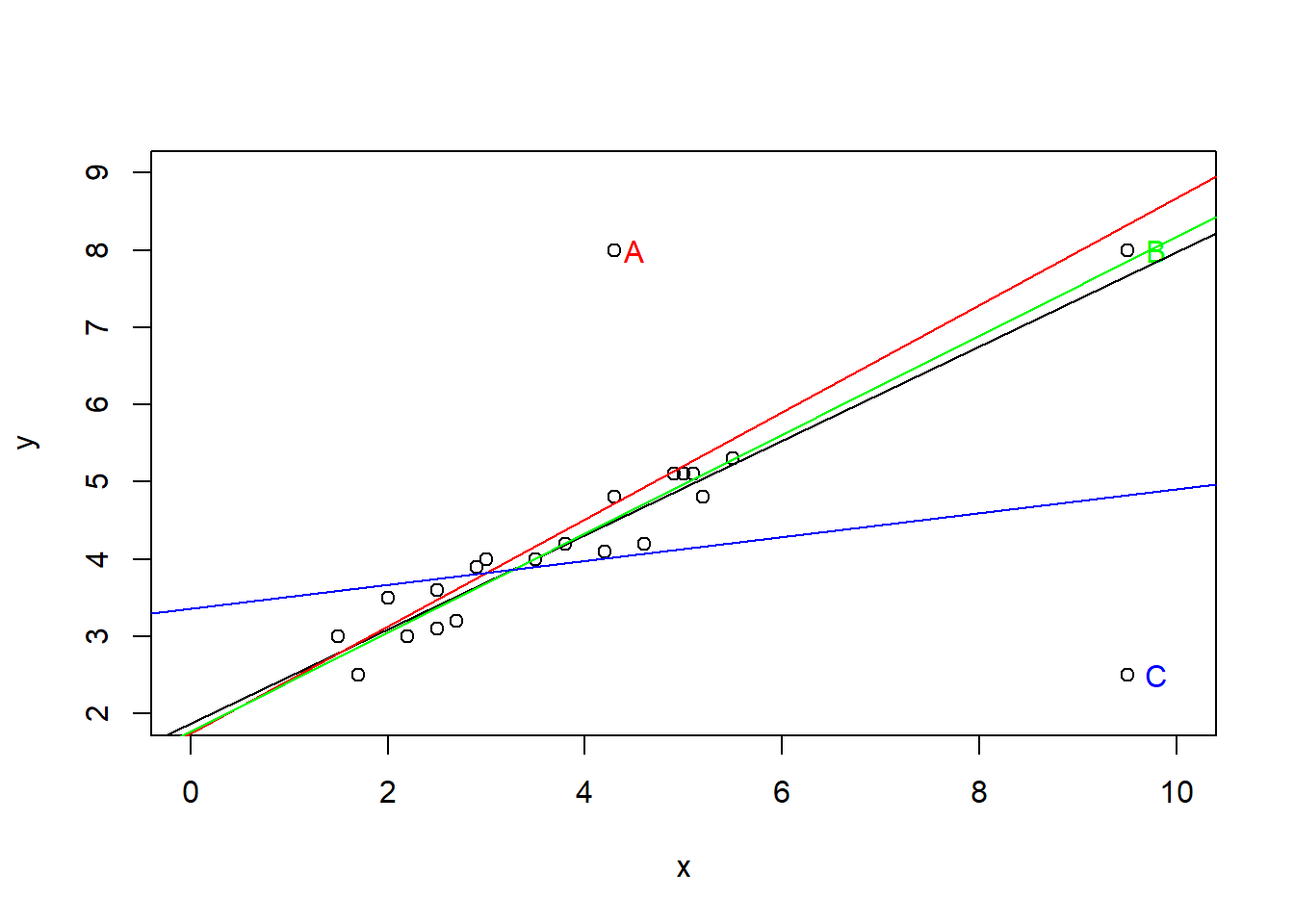
G Details. Results from four regression models
\[\begin{matrix} \begin{array}{c} \text{Results from Four Regressions} \end{array}\\\scriptsize \begin{array}{l|rrrrr} \hline \text{Data} & b_0 & b_1 & s & R^2(\%) & t(b_1) \\ \hline \text{19 Base Points} & 1.869 & 0.611 & 0.288 & 89.0 & 11.71 \\ \text{19 Base Points} ~+~ A & 1.750 & 0.693 & 0.846 & 53.7 & 4.57 \\ \text{19 Base Points} ~+~ B & 1.775 & 0.640 & 0.285 & 94.7 & 18.01 \\ \text{19 Base Points} ~+~ C & 3.356 & 0.155 & 0.865 & 10.3 & 1.44 \\ \hline \end{array} \end{matrix}\]
2.5.2 Exercise. Assessing outliers in lottery sales
Assignment Text
In an earlier video, we made a scatter plot of population versus sales. This plot exhibits an outlier; the point in the upper left-hand side of the plot represents a zip code that includes Kenosha, Wisconsin. Sales for this zip code are unusually high given its population.
This exercise summarizes the regression fit both with and without this zip code in order to see how robust our results are to the inclusion of this unusual observation.
Instructions
- A basic linear regression fit of population on sales has already been fit in the object
model_blr. Re-fit this same model to the data, this time omitting Kenosha (observation number 9). - Plot these two least squares fitted lines superimposed on the full data set.
- What is the effect on the distribution of residuals by removing this point? Calculate a normal qq plot with and without Kenosha.