Chapter 4 Variable Selection
Chapter description
This chapter describes tools and techniques to help you select variables to enter into a linear regression model, beginning with an iterative model selection process. In applications with many potential explanatory variables, automatic variable selection procedures are available that will help you quickly evaluate many models. Nonetheless, automatic procedures have serious limitations including the inability to account properly for nonlinearities such as the impact of unusual points; this chapter expands upon the Chapter 2 discussion of unusual points. It also describes collinearity, a common feature of regression data where explanatory variables are linearly related to one another. Other topics that impact variable selection, including out-of-sample validation, are also introduced.
4.1 An iterative approach to data analysis and modeling
In this section, you learn how to:
- Describe the iterative approach to data analysis and modeling.
4.1.1 Video
Video Overhead Details
A Details. Iterative approach
- Model formulation stage
- Fitting
- Diagnostic checking - the data and model must be consistent with one another before additional inferences can be made.
plot.new()
par(mar=c(0,0,0,0), cex=0.9)
plot.window(xlim=c(0,18),ylim=c(-5,5))
text(1,3,labels="DATA",adj=0, cex=0.8)
text(1,0,labels="PLOTS",adj=0, cex=0.8)
text(1,-3,labels="THEORY",adj=0, cex=0.8)
text(3.9,0,labels="MODEL\nFORMULATION",adj=0, cex=0.8)
text(8.1,0,labels="FITTING",adj=0, cex=0.8)
text(11,0,labels="DIAGNOSTIC\nCHECKING",adj=0, cex=0.8)
text(15,0,labels="INFERENCE",adj=0, cex=0.8)
text(14.1,0.5,labels="OK",adj=0, cex=0.6)
rect(0.8,2.0,2.6,4.0)
arrows(1.7,2.0,1.7,1.0,code=2,lwd=2,angle=25,length=0.10)
rect(0.8,-1.0,2.6,1.0)
arrows(1.7,-2.0,1.7,-1.0,code=2,lwd=2,angle=25,length=0.10)
rect(0.8,-4.0,2.6,-2.0)
arrows(2.6,0,3.2,0,code=2,lwd=2,angle=25,length=0.10)
x<-c(5,7.0,5,3.2)
y<-c(2,0,-2,0)
polygon(x,y)
arrows(7.0,0,8.0,0,code=2,lwd=2,angle=25,length=0.10)
rect(8.0,-1.0,9.7,1.0)
arrows(9.7,0,10.2,0,code=2,lwd=2,angle=25,length=0.10)
x1<-c(12,14.0,12,10.2)
y1<-c(2,0,-2,0)
polygon(x1,y1)
arrows(14.0,0,14.8,0,code=2,lwd=2,angle=25,length=0.10)
rect(14.8,-1.0,17.5,1.0)
arrows(12,-2.0,12,-3,code=2,lwd=2,angle=25,length=0.10)
arrows(12,-3.0,5,-3,code=2,lwd=2,angle=25,length=0.10)
arrows(5,-3.0,5,-2,code=2,lwd=2,angle=25,length=0.10)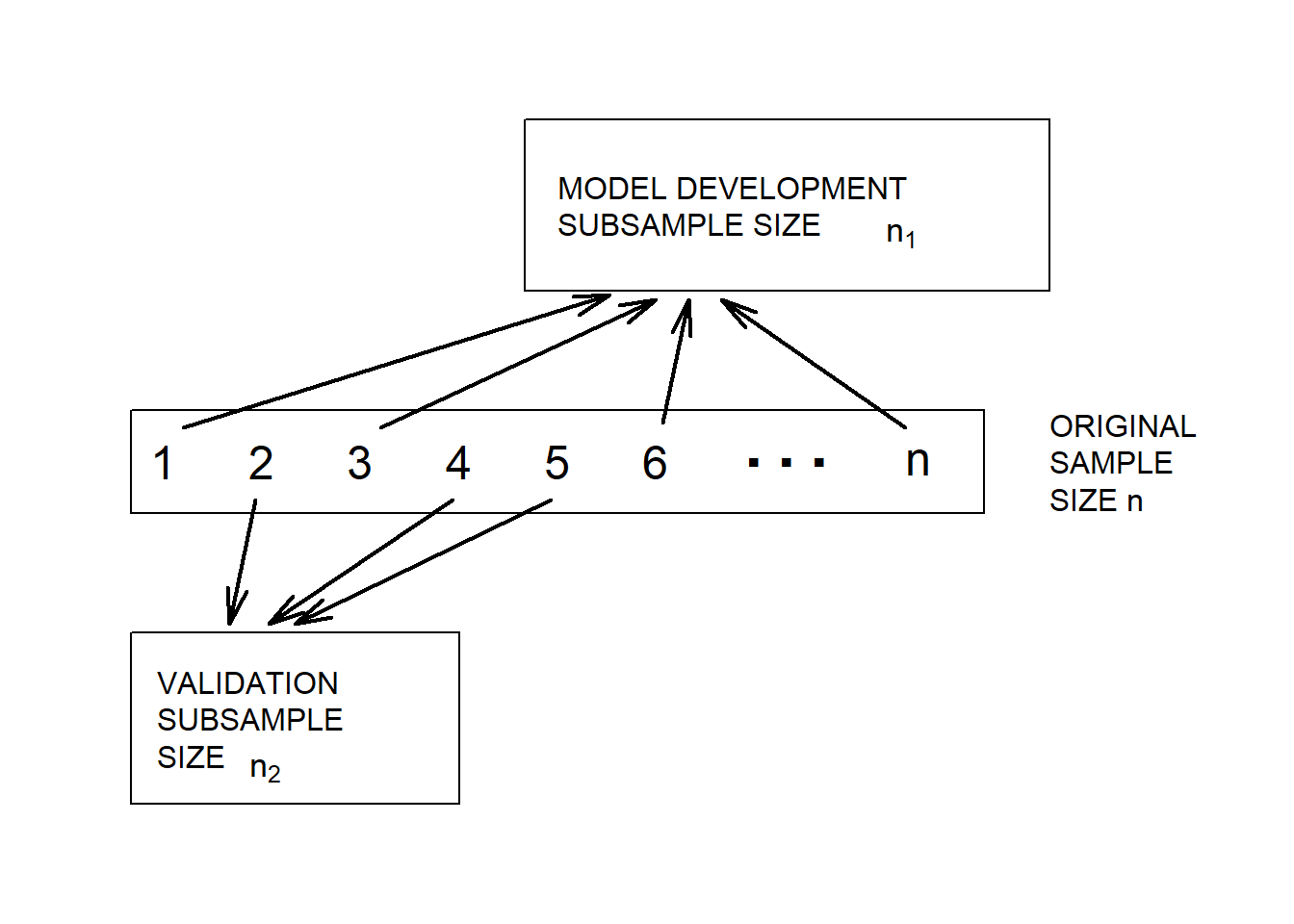
B Details. Many possible models
\[ \begin{array}{l|r} \hline \text{E }y = \beta _{0} & \text{1 model with no variables } \\ \text{E }y = \beta _{0}+\beta_1 x_{i}, & \text{4 models with one variable} \\ \text{E }y = \beta _{0}+\beta_1 x_{i}+\beta_{2} x_{j}, & \text{6 models with two variables} \\ \text{E }y = \beta _{0}+\beta_{1} x_{1}+\beta_{2} x_{j} +\beta_{3} x_{k},& \text{4 models with three variables} \\ \text{E }y = \beta_{0} + \beta_{1} x_{1} + \beta_{2} x_{2} +\beta_{3} x_{3}+\beta_{4} x_{4} & \text{1 model with all variables} \\ \hline \end{array} \]
- With k explanatory variables, there are \(2^k\) possible linear models
- There are infinitely many nonlinear ones!!
C Details. Model validation
- Model validation is the process of confirming our proposed model.
- Concern: data-snooping - fitting many models to a single set of data.
- Response to concern: out-of-sample validation.
- Divide the data into model development, or training and validation, or test, subsamples.
par(mai=c(0,0.1,0,0))
plot.new()
plot.window(xlim=c(0,18),ylim=c(-10,10))
rect(1,-1.2,14,1.2)
rect(7,4,15,8)
rect(1,-8,6,-4)
x<-seq(1.5,9,length=6)
y<-rep(0,6)
text(x,y,labels=c(1:6),cex=1.5)
x1<-seq(10.5,11.5,length=3)
y1<-rep(0,3)
text(x1,y1,labels=rep(".",3),cex=3)
text(13,0,labels="n",cex=1.5)
text(15,0,labels="ORIGINAL\nSAMPLE\nSIZE n",adj=0)
text(7.5,6,labels="MODEL DEVELOPMENT\nSUBSAMPLE SIZE",adj=0)
text(12.5,5.3, expression(n[1]), adj=0, cex=1.1)
text(1.4,-6,labels="VALIDATION\nSUBSAMPLE\nSIZE",adj=0)
text(2.8,-7.2,expression(n[2]),adj=0, cex=1.1)
arrows(1.8,0.8,8.3,3.9,code=2,lwd=2,angle=15,length=0.2)
arrows(4.8,0.8,9,3.8,code=2,lwd=2,angle=15,length=0.2)
arrows(9.1,0.9,9.5,3.8,code=2,lwd=2,angle=15,length=0.2)
arrows(12.8,0.8,10,3.8,code=2,lwd=2,angle=15,length=0.2)
arrows(2.9,-0.9,2.5,-3.8,code=2,lwd=2,angle=15,length=0.2)
arrows(5.9,-0.9,3.1,-3.8,code=2,lwd=2,angle=15,length=0.2)
arrows(7.4,-0.9,3.5,-3.8,code=2,lwd=2,angle=15,length=0.2)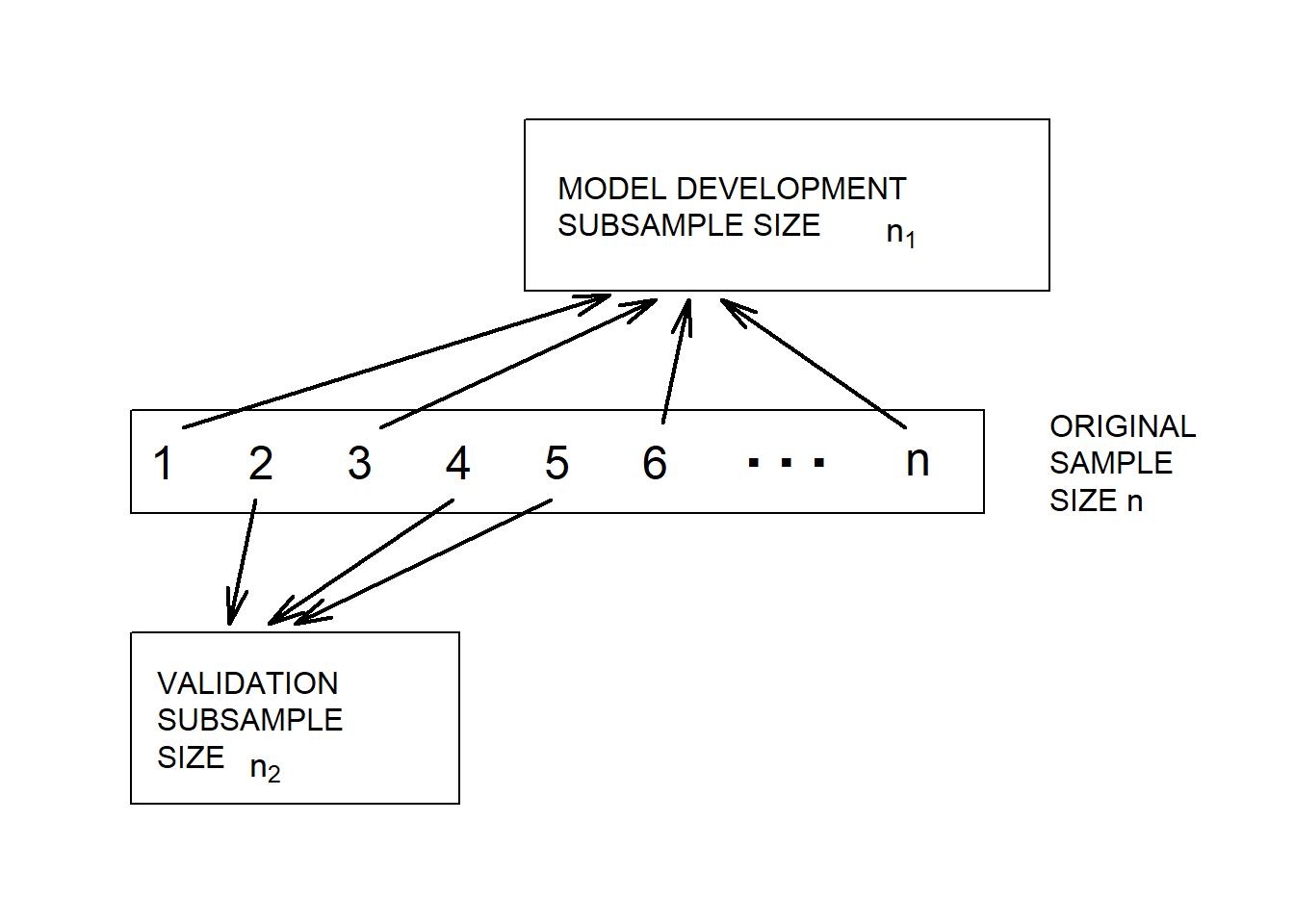
###MC Exercise. An iterative approach to data modeling
Which of the following is not true?
- A. Diagnostic checking reveals symptoms of mistakes made in previous specifications.
- B. Diagnostic checking provides ways to correct mistakes made in previous specifications.
- C. Model formulation is accomplished by using prior knowledge of relationships.
- D. Understanding theoretical model properties is not really helpful when matching a model to data or inferring general relationships based on the data.
4.2 Automatic variable selection procedures
In this section, you learn how to:
- Identify some examples of automatic variable selection procedures
- Describe the purpose of automatic variable selection procedures and their limitations
- Describe “data-snooping”
4.2.1 Video
Video Overhead Details
A Details. Classic stepwise regression algorithm
Suppose that the analyst has identified one variable as the outcome, \(y\), and \(k\) potential explanatory variables, \(x_1, x_2, \ldots, x_k\).
- (i). Consider all possible regressions using one explanatory variable. Choose the one with the highest t-statistic.
- (ii). Add a variable to the model from the previous step. The variable to enter is with the highest t-statistic.
- (iii). Delete a variable to the model from the previous step. Delete the variable with the small t-statistic if the statistic is less than, e.g., 2 in absolute value.
- (iv). Repeat steps (ii) and (iii) until all possible additions and deletions are performed.
B Details. Drawbacks of stepwise regression
- The procedure “snoops” through a large number of models and may fit the data “too well.”
- There is no guarantee that the selected model is the best.
- The algorithm does not consider models that are based on nonlinear combinations of explanatory variables.
- It ignores the presence of outliers and high leverage points.
C Details. Data-snooping in stepwise regression
- Generate \(y\) and \(x_1 - x_{50}\) using a random number generator
- By design, there is no relation between \(y\) and \(x_1 - x_{50}\).
- But, through stepwise regression, we “discover” a relationship that explains 14% of the variation!!!
Call: lm(formula = y ~ xvar27 + xvar29 + xvar32, data = X)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.04885 0.09531 -0.513 0.6094
xvar27 0.21063 0.09724 2.166 0.0328 *
xvar29 0.24887 0.10185 2.443 0.0164 *
xvar32 0.25390 0.09823 2.585 0.0112 *
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9171 on 96 degrees of freedom
Multiple R-squared: 0.1401, Adjusted R-squared: 0.1132
F-statistic: 5.212 on 3 and 96 DF, p-value: 0.002233D Details. Variants of stepwise regression
This uses the R function step()
- The option
directioncan be used to change how variables enter- Forward selection. Add one variable at a time without trying to delete variables.
- Backwards selection. Start with the full model and delete one variable at a time without trying to add variables.
- The option
scopecan be used to specify which variables must be included
E Details. Automatic variable selection procedures
- Stepwise regression is a type of automatic variable selection procedure.
- These procedures are useful because they can quickly search through several candidate models. They mechanize certain routine tasks and are excellent at discovering patterns in data.
- They are so good at detecting patterns that they analyst must be wary of overfitting (data-snooping)
- They can miss certain patterns (nonlinearities, unusual points)
- A model suggested by automatic variable selection procedures should be subject to the same careful diagnostic checking procedures as a model arrived at by any other means
4.2.2 Exercise. Data-snooping in stepwise regression
Assignment Text
Automatic variable selection procedures, such as the classic stepwise regression algorithm, are very good at detecting patterns. Sometimes they are too good in the sense that they detect patterns in the sample that are not evident in the population from which the data are drawn. The detect “spurious” patterns.
This exercise illustrates this phenomenom by using a simulation, designed so that the outcome variable (y) and the explanatory variables are mutually independent. So, by design, there is no relationship between the outcome and the explanatory variables.
As part of the code set-up, we have n = 100 observations generated of the outcome y and 50 explanatory variables, xvar1 through xvar50. As anticipated, collections of explanatory variables are not statistically significant. However, with the step() function, you will find some statistically significant relationships!
Instructions
- Fit a basic linear regression model and MLR model with the first ten explanatory variables. Compare the models via an F test.
- Fit a multiple linear regression model with all fifty explanatory variables. Compare this model to the one with ten variables via an F test.
- Use the
stepfunction to find the best model starting with the fitted model containing all fifty explanatory variables and summarize the fit.
Hint. The code shows stepwise regression using BIC, a criterion that results in simpler models than AIC. For AIC, use the option k=2 in the [step()] function (the default)
4.3 Residual analysis
In this section, you learn how to:
- Explain how residual analysis can be used to improve a model specification
- Use relationships between residuals and potential explanatory variables to improve model specification
4.3.1 Video
Video Overhead Details
A Details. Residual analysis
- Use \(e_i = y_i - \hat{y}_i\) as the ith residual.
- Later, I will discuss rescaling by, for example, \(s\), to get a standardized residual.
- Role of residuals: If the model formulation is correct, then residuals should be approximately equal to random errors or “white noise.”
- Method of attack: Look for patterns in the residuals. Use this information to improve the model specification.
B Details. Using residuals to select explanatory variables
- Residual analysis can help identify additional explanatory variables that may be used to improve the formulation of the model.
- If the model is correct, then residuals should resemble random errors and contain no discernible patterns.
- Thus, when comparing residuals to explanatory variables, we do not expect any relationships.
- If we do detect a relationship, then this suggests the need to control for this additional variable.
C Details. Detecting relationships between residuals and explanatory variables
- Calculate summary statistics and display the distribution of residuals to identify outliers.
- Calculate the correlation between the residuals and additional explanatory variables to search for linear relationships.
- Create scatter plots between the residuals and additional explanatory variables to search for nonlinear relationships.
4.3.2 Exercise. Residual analysis and risk manager survey
Assignment Text
This exercise examines data, pre-loaded in the dataframe survey, from a survey on the cost effectiveness of risk management practices. Risk management practices are activities undertaken by a firm to minimize the potential cost of future losses, such as the event of a fire in a warehouse or an accident that injures employees. This exercise develops a model that can be used to make statements about cost of managing risks.
A measure of risk management cost effectiveness, logcost, is the outcome variable. This variable is defined as total property and casualty premiums and uninsured losses as a proportion of total assets, in logarithmic units. It is a proxy for annual expenditures associated with insurable events, standardized by company size. Explanatory variables include
logsize, the logarithm of total firm assets, and indcost, a measure of the firm’s industry risk.
Instructions
- Fit and summarize a MLR model using
logcostas the outcome variable andlogsizeandindcostas explanatory variables. - Plot residuals of the fitted model versus
indcostand superimpose a locally fitted line using theRfunction lowess(). - Fit and summarize a MLR model of
logcostonlogsize,indcostand a squared version ofindcost. - Plot residuals of the fitted model versus `indcost’ and superimpose a locally fitted line using lowess().
Hint. You can access model residuals using mlr.survey1$residuals or mlr.survey1($residuals)
4.3.3 Exercise. Added variable plot and refrigerator prices
Assignment Text
What characteristics of a refrigerator are important in determining its price (price)? We consider here several characteristics of a refrigerator, including the size of the
refrigerator in cubic feet (rsize), the size of the freezer compartment in cubic feet (fsize), the average amount of money spent per year to operate the refrigerator (ecost, for energy cost), the number of shelves in the refrigerator and freezer doors (shelves), and the number of features (features). The features variable includes shelves for cans, see-through crispers, ice makers, egg racks and so on.
Both consumers and manufacturers are interested in models of refrigerator prices. Other things equal, consumers generally prefer larger refrigerators with lower energy costs that have more features. Due to forces of supply and demand, we would expect consumers to pay more for these refrigerators. A larger refrigerator with lower energy costs that has more features at the similar price is considered a bargain to the consumer. How much extra would the consumer be willing to pay for this additional space? A model of prices for refrigerators on the market provides some insight to this question.
To this end, we analyze data from n = 37 refrigerators.
Instructions
# Pre-exercise code
Refrig <- read.table("CSVData\\Refrig.csv", header = TRUE, sep = ",")
summary(Refrig)
Refrig1 <- Refrig[c("price", "ecost", "rsize", "fsize", "shelves", "s_sq_ft", "features")]
round(cor(Refrig1), digits = 3)
refrig_mlr1 <- lm(price ~ rsize + fsize + shelves + features, data = Refrig)
summary(refrig_mlr1)
Refrig$residuals1 <- residuals(refrig_mlr1)
refrig_mlr2 <- lm(ecost ~ rsize + fsize + shelves + features, data = Refrig)
summary(refrig_mlr2)
Refrig$residuals2 <- residuals(refrig_mlr2)
plot(Refrig$residuals2, Refrig$residuals1)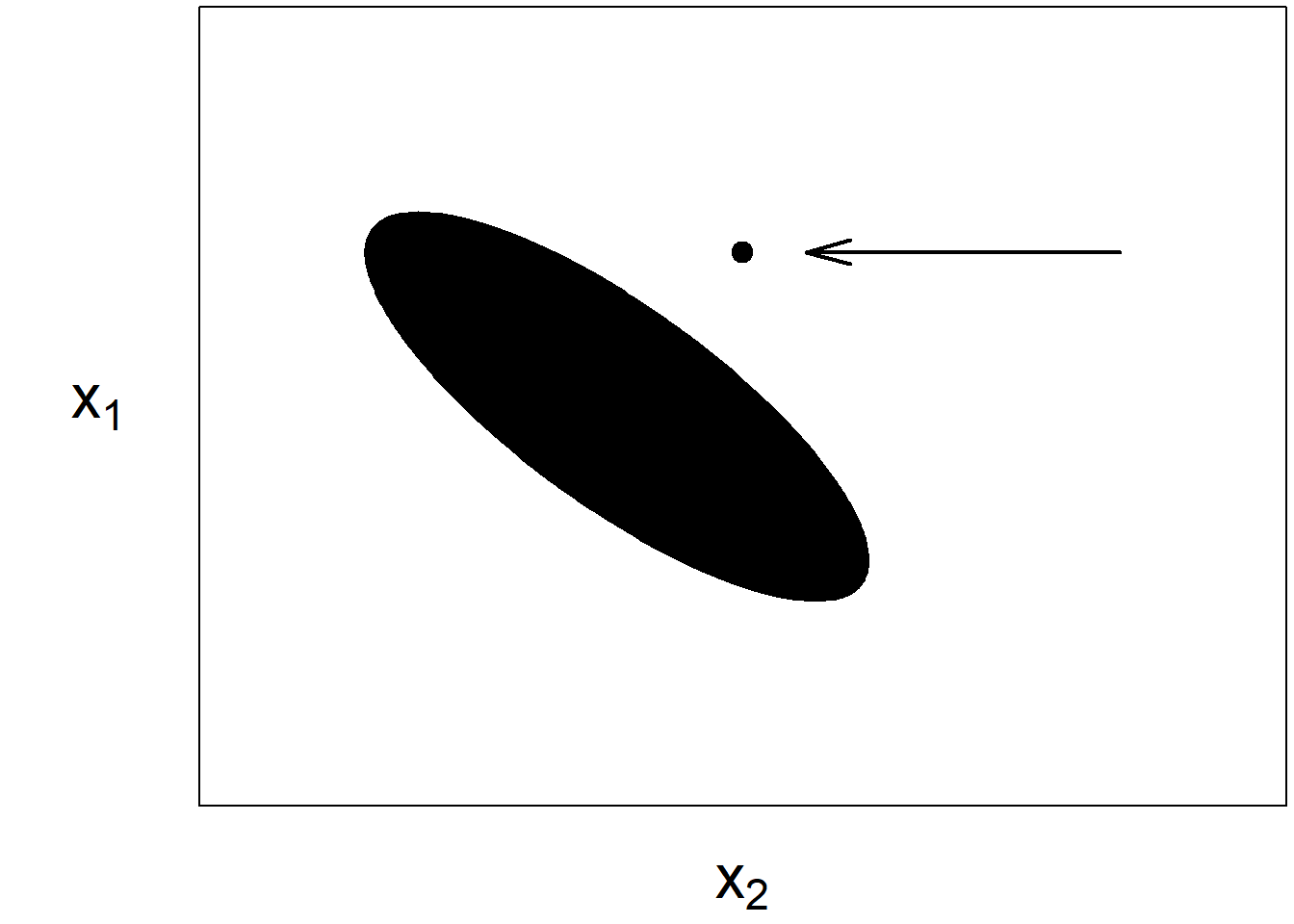
#library(Rcmdr)
#refrig_mlr3 <- lm(price ~ rsize + fsize + shelves + features + ecost, data = Refrig)
#avPlots(refrig_mlr3, terms = "ecost") price ecost rsize fsize
Min. : 460.0 Min. :60.00 Min. :12.6 Min. :4.100
1st Qu.: 545.0 1st Qu.:66.00 1st Qu.:12.9 1st Qu.:4.400
Median : 590.0 Median :68.00 Median :13.2 Median :5.100
Mean : 626.4 Mean :70.51 Mean :13.4 Mean :5.184
3rd Qu.: 685.0 3rd Qu.:75.00 3rd Qu.:13.9 3rd Qu.:5.700
Max. :1200.0 Max. :94.00 Max. :14.7 Max. :7.400
shelves s_sq_ft features
Min. :1.000 Min. :20.60 Min. : 1.000
1st Qu.:2.000 1st Qu.:23.40 1st Qu.: 2.000
Median :2.000 Median :24.00 Median : 3.000
Mean :2.514 Mean :24.53 Mean : 3.459
3rd Qu.:3.000 3rd Qu.:25.50 3rd Qu.: 5.000
Max. :5.000 Max. :30.20 Max. :12.000
price ecost rsize fsize shelves s_sq_ft features
price 1.000 0.522 -0.024 0.720 0.400 0.155 0.697
ecost 0.522 1.000 -0.033 0.855 0.188 0.058 0.334
rsize -0.024 -0.033 1.000 -0.235 -0.363 0.401 -0.096
fsize 0.720 0.855 -0.235 1.000 0.251 0.110 0.439
shelves 0.400 0.188 -0.363 0.251 1.000 -0.527 0.160
s_sq_ft 0.155 0.058 0.401 0.110 -0.527 1.000 0.083
features 0.697 0.334 -0.096 0.439 0.160 0.083 1.000
Call:
lm(formula = price ~ rsize + fsize + shelves + features, data = Refrig)
Residuals:
Min 1Q Median 3Q Max
-128.200 -34.963 7.081 28.716 155.096
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -698.89 302.60 -2.310 0.02752 *
rsize 56.50 20.56 2.748 0.00977 **
fsize 75.40 13.93 5.414 5.96e-06 ***
shelves 35.92 11.08 3.243 0.00277 **
features 25.16 5.04 4.992 2.04e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 68.11 on 32 degrees of freedom
Multiple R-squared: 0.789, Adjusted R-squared: 0.7626
F-statistic: 29.92 on 4 and 32 DF, p-value: 2.102e-10
Call:
lm(formula = ecost ~ rsize + fsize + shelves + features, data = Refrig)
Residuals:
Min 1Q Median 3Q Max
-7.8483 -4.3064 0.5154 2.6324 9.3596
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -14.2165 20.9365 -0.679 0.5020
rsize 2.8744 1.4225 2.021 0.0517 .
fsize 8.9085 0.9636 9.245 1.49e-10 ***
shelves 0.2895 0.7664 0.378 0.7081
features -0.2006 0.3487 -0.575 0.5692
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4.712 on 32 degrees of freedom
Multiple R-squared: 0.7637, Adjusted R-squared: 0.7342
F-statistic: 25.86 on 4 and 32 DF, p-value: 1.247e-094.4 Unusual observations
In this section, you learn how to:
- Compare and contrast three alternative definitions of a standardized residual
- Evaluate three alternative options for dealing with outliers
- Assess the impact of a high leverage observation
- Evaluate options for dealing with high leverage observations
- Describe the notion of influence and Cook’s Distance for quantifying influence
4.4.1 Video
Video Overhead Details
A Details. Unusual observations
- Regression coefficients can be expressed as (matrix) weighted averages of outcomes
- Averages, even weighted averages can be strongly influenced by unusual observations
- Observations may be unusual in the y direction or in the X space
- For unusual in the y direction, we use a residual \(e = y - \hat{y}\)
- By subtracting the fitted value \(\hat{y}\), we look to the y distance from the regression plane
- In this way, we “control” for values of explanatory variables
B Details. Standardized residuals
We standardize residuals so that we can focus on relationships of interest and achieve carry-over of experience from one data set to another.
Three commonly used definitions of standardize residuals are:
\[ \text{(a) }\frac{e_i}{s}, \ \ \ \text{ (b) }\frac{e_i}{s\sqrt{1-h_{ii}}}, \ \ \ \text{(c)}\frac{e_i}{s_{(i)}\sqrt{1-h_{ii}}}. \]
- First choice is simple
- Second choice, from theory, \(\mathrm{Var}(e_i)=\sigma ^{2}(1-h_{ii}).\) Here, \(h_{ii}\) is the \(i\)th leverage (defined later).
- Third choice is termed “studentized residuals”. Idea: numerator is independent of the denominator.
C Details. Outlier - an unusal standardized residual
- An outlier is an observation that is not well fit by the model; these are observations where the residual is unusually large.
- Unusual means what? Many packages mark a point if the |standardized residual| > 2.
- Options for handling outliers
- Ignore them in the analysis but be sure to discuss their effects.
- Delete them from the data set (but be sure to discuss their effects).
- Create a binary variable to indicator their presence. (This will increase your \(R^2\)!)
D Details. High leverage points
- A high leverage point is an observation that is “far away” in the \(x\)-space from others.
- One can get a feel for high leverage observations by looking a summary statistics (mins, maxs) for each explanatory variable.
- Options for dealing with high leverage points are comparable to outliers, we can ignore their effects, delete them, or mark them with a binary indicator variable.
E Details. High leverage point graph
library(cluster)
#library(MASS)
par(mar=c(3.2,5.4,.2,.2))
plot(1,5,type="p",pch=19,cex=1.5,xlab="",ylab="",cex.lab=1.5,xaxt="n",yaxt="n",xlim=c(-3,5),ylim=c(-12,12))
mtext(expression(x[2]), side=1,line=2, cex=2.0)
mtext(expression(x[1]), side=2, line=2, las=2, cex=2.0)
arrows(1.5,5,4,5,code=1,lwd=2,angle=15,length=0.25)
xycov<-matrix(c(2, -5,-5, 20),nrow=2,ncol=2)
xyloc<-matrix(c(0, 0),nrow=1,ncol=2)
polygon(ellipsoidPoints(xycov, d2 = 2, loc=xyloc),col="black")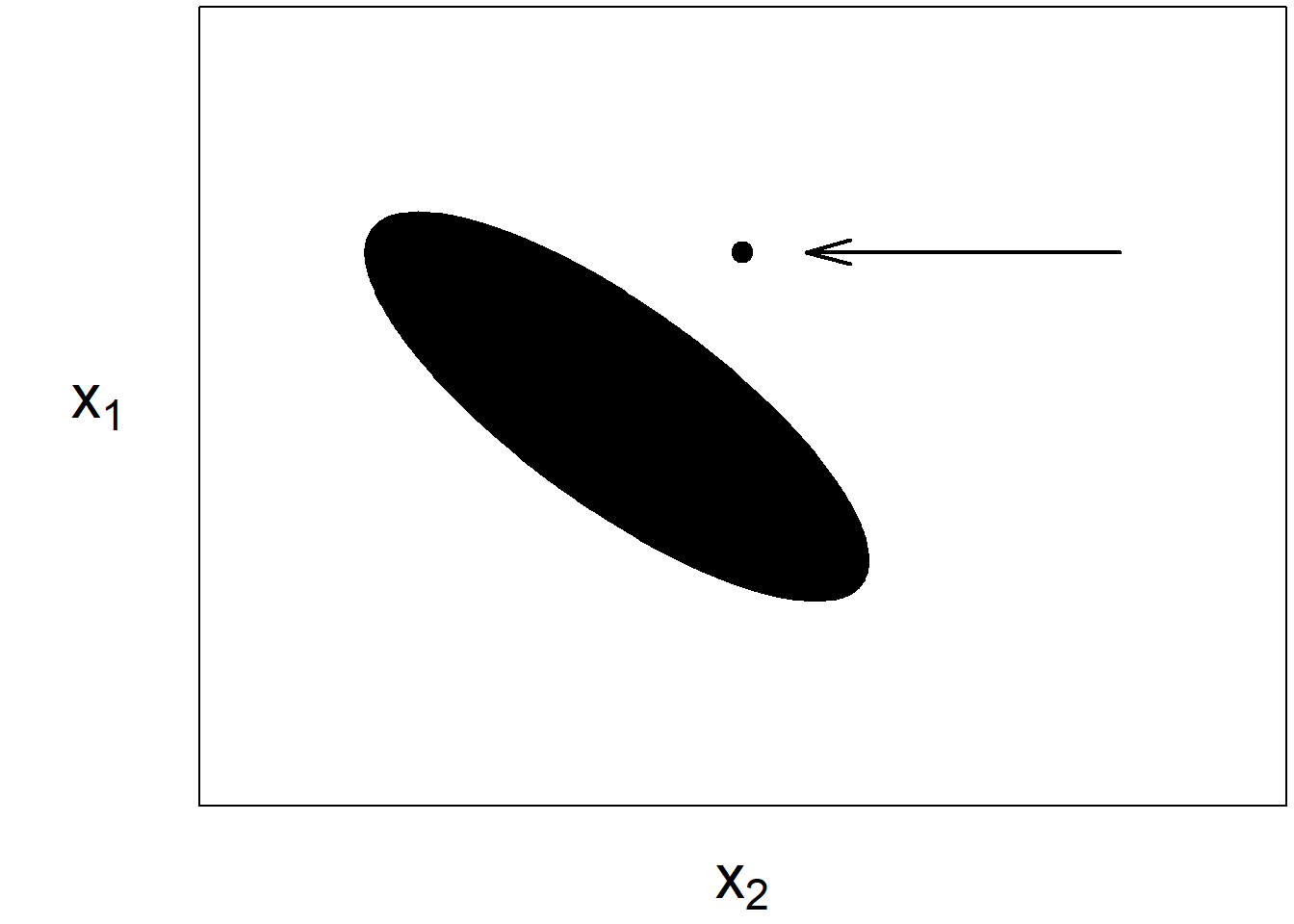
F Details. Leverage
- Using matrix algebra, one can express the ith fitted value as a linear combination of observations
\[ \hat{y}_{i} = h_{i1} y_{1} + \cdots +h_{ii}y_{i}+\cdots+h_{in}y_{n}. \]
- The term \(h_{ii}\) is known as the ith leverage
- The larger the value of \(h_{ii}\), the greater the effect of the ith observation \(y_i\) on the ith fitted value \(\hat{y}_i\).
- Statistical routines have values of the leverage coded, so computing this quantity. The key thing to know is that \(h_{ii}\) is based solely on the explanatory variables. If you change the \(y\) values, the leverage does not change.
- As a commonly used rule of thumb, a leverage is deemed to be “unusual” if its value exceeds three times the average (= number of regression coefficients divided by the number of observations.)
4.4.2 Exercise. Outlier example
In chapter 2, we consider a fictitious data set of 19 “base” points plus three different types of unusual points. In this exercise, we consider the effect of one unusal point, “C”, this both an outlier (unusual in the “y” direction) and a high leverage point (usual in the x-space). The data have been pre-loaded in the dataframe outlrC.
Instructions
- Fit a basic linear regression model of
yonxand store the result in an object. - Use the function rstandard() to extract the standardized residuals from the fitted regression model object and summarize them.
- Use the function hatvalues() to extract the leverages from the model fitted and summarize them.
- Plot the standardized residuals versus the leverages to see the relationship between these two measures that calibrate how unusual an observation is.
4.4.3 Exercise. High leverage and risk manager survey
Assignment Text
In a prior exercise, we fit a regression model of logcost on logsize, indcost and a squared version of indcost. This model is summarized in the object mlr_survey2. In this exercise, we examine the robustness of the model to unusual observations.
Instructions
- Use the
Rfunctions rstandard() and hatvalues() to extract the standardized residuals and leverages from the model fitted. Summarize the distributions graphically. - You will see that there are two observations where the leverages are high, numbers 10 and 16. On looking at the dataset, these turn out to be observations in a high risk industry. Create a histogram of the variable
indcostto corroborate this. - Re-run the regression omitting observations 10 and 16. Summarize this regression and the regression in the object
mlr_survey2, noting differences in the coefficients.
4.5 Collinearity
In this section, you learn how to:
- Define collinearity and describe its potential impact on regression inference
- Define a variance inflation factor and describe its effect on a regression coefficients standard error
- Describe rules of thumb for assessing collinearity and options for model reformulation in the presence of severe collinearity
- Compare and contrast effects of leverage and collinearity
4.5.1 Video
Video Overhead Details
A Details. Collinearity
- Collinearity, or multicollinearity, occurs when one explanatory variable is, or nearly is, a linear combination of the other explanatory variables.
- Useful to think of the explanatory variables as being highly correlated with one another.
- Collinearity neither precludes us from getting good fits nor from making predictions of new observations.
- Estimates of error variances and, therefore, tests of model adequacy, are still reliable.
- In cases of serious collinearity, standard errors of individual
regression coefficients can be large.
- With large standard errors, individual regression coefficients may not be meaningful.
- Because a large standard error means that the corresponding t-ratio is small, it is difficult to detect the importance of a variable.
B Details. Quantifying collinearity
A common way to quantify collinearity is through the variance inflation factor (VIF).
- Suppose that the set of explanatory variables is labeled \(x_{1},x_{2},\dots,x_{k}\).
- Run the regression using \(x_{j}\) as the “outcome” and the other \(x\)’s as the explanatory variables.
- Denote the coefficient of determination from this regression by \(R_j^2\).
- Define the variance inflation factor
\[ VIF_{j}=\frac{1}{1-R_{j}^{2}},\ \ \ \text{ for } j = 1,2,\ldots, k. \]
C Details. Options for handling collinearity
- Rule of thumb: When \(VIF_{j}\) exceeds 10 (which is equivalent to \(R_{j}^{2}>90\%\)), we say that severe collinearity exists. This may signal is a need for action.
- Recode the variables by “centering” - that is, subtract the mean and divide by the standard deviation.
- Ignore the collinearity in the analysis but comment on it in the interpretation. Probably the most common approach.
- Replace one or more variables by auxiliary variables or transformed versions.
- Remove one or more variables. Easy. Which One? is hard.
- Use interpretation. Which variable(s) do you feel most comfortable with?
- Use automatic variable selection procedures to suggest a model.
4.5.2 Exercise. Collinearity and term life
Assignment Text We have seen that adding an explanatory variable \(x^2\) to a model is sometimes helpful even though it is perfectly related to \(x\) (such as through the function \(f(x)=x^2\)). But, for some data sets, higher order polynomials and interactions can be approximately linearly related (depending on the range of the data).
This exercise returns to our term life data set Term1 (preloaded) and demonstrates that collinearity can be severe when introducing interaction terms.
Instructions
- Fit a MLR model of
logfaceon explantory variableseducation,numhhandlogincome - Use the function vif() from the
carpackage (preloaded) to calculate variance inflation factors. - Fit and summarize a MLR model of
logfaceon explantory variableseducation,numhhandlogincomewith an interaction betweennumhhandlogincome, then extract variance inflation factors.
Hint. If the car package is not available to you, then you could calculate vifs using the [lm()] function, treating each variable separately. For example
1/(1-summary(lm(education ~ numhh + logincome, data = Term1))$r.squared)
gives the education vif.
4.6 Selection criteria
In this section, you learn how to:
- Summarize a regression fit using alternative goodness of fit measures
- Validate a model using in-sample and out-of-sample data to mitigate issues of data-snooping
- Compare and contrast SSPE and PRESS statistics for model validation
4.6.1 Video
Video Overhead Details
A Details. Goodness of fit
- Criteria that measure the proximity of the fitted model and realized data are known as goodness of fit statistics.
- Basic examples include:
- the coefficient of determination \((R^{2})\),
- an adjusted version \((R_{a}^{2})\),
- the size of the typical error \((s)\), and
- \(t\)-ratios for each regression coefficient.
A Details. Goodness of fit
A general measure is Akaike’s Information Criterion, defined as
\[ AIC = -2 \times (fitted~log~likelihood) + 2 \times (number~of~parameters) \]
- For model comparison, the smaller the \(AIC,\) the better is the fit.
- This measures balances the fit (in the first part) with a penalty for complexity (in the second part)
- It is a general measure - for linear regression, it reduces to
\[ AIC = n \ln (s^2) + n \ln (2 \pi) +n +k + 3 . \]
- So, selecting a model to minimize \(s\) or \(s^2\) is equivalent to model selection based on minimizing \(AIC\) (same k).
C Details. Out of sample validation
- When you choose a model to minimize \(s\) or \(AIC\), it is based on how well the model fits the data at hand, or the model development, or training, data
- As we have seen, this approach is susceptible to overfitting.
- A better approach is to validate the model on a model validation, or test data set, held out for this purpose.
D Details. Out of sample validation procedure
- Using the model development subsample, fit a candidate model.
- Using the Step (ii) model and the explanatory variables from the validation subsample, “predict” the dependent variables in the validation subsample, \(\hat{y}_i\), where \(i=n_{1}+1,...,n_{1}+n_{2}\).
- Calc the *sum of absolute prediction errors**
\[SAPE=\sum_{i=n_{1}+1}^{n_{1}+n_{2}} |y_{i}-\hat{y}_{i}| . \]
Repeat Steps (i) through (iii) for each candidate model. Choose the model with the smallest SAPE.
E Details. Cross - validation
- With out-of-sample validation, the statistic depends on a random split between in-sample and out-of-sample data (a problem for data sets that are not large)
- Alternatively, one may use cross-validation
- Use a random mechanism to split the data into k subsets, (e.g., 5-10)
- Use the first k-1 subsamples to estimate model parameters. Then, “predict” the outcomes for the kth subsample and use SAE to summarize the fit
- Repeat this by holding out each of the k sub-samples, summarizing with a cumulative SAE.
- Repeat these steps for several candidate models.
- Choose the model with the lowest cumulative SAE statistic.
4.6.2 Exercise. Cross-validation and term life
Assignment Text
Here is some sample code to give you a better feel for cross-validation.
The first part of the randomly re-orders (“shuffles”) the data. It also identifies explanatory variables explvars.
The function starts by pulling out only the needed data into cvdata. Then, for each subsample, a model is fit based on all the data except for the subsample, in train_mlr with the subsample in test. This is repeated for each subsample, then results are summarized.
Show Code
Instructions
- Calculate the cross-validation statistic using only logarithmic income,
logincome. - Calculate the cross-validation statistic using
logincome,educationandnumhh. - Calculate the cross-validation statistic using
logincome,education,numhhandmarstat.
The best model has the lowest cross-validation statistic.